Python 序列
列表
列表是Python终于的重要的组成之一。在列表中的所有元素都放在一对中括号“[ ]”中,相邻元素之间用逗号隔开。
创建列表
格式如下:
student = [‘name’,’name’,’age’]
也可以通过list()函数将元组、字符串、字典或者其他类型的可迭代对象转化为列表,如下:
num = list((1,2,3,4,5,6,7,8,9))

删除列表
删除列表中的单个元素
1 | list = [5,2,'h','e','r','t','z','i'] |
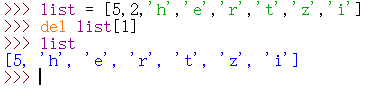
删除整个列表
1 | list = [5,2,'h','e','r','t','z','i'] |
在列表尾部添加单个元素
1 | list = [5,2,'h','e','r','t','z','i'] |

在列表尾部添加列表 L
1 | list = [5,2,'h','e','r','t','z','i'] |
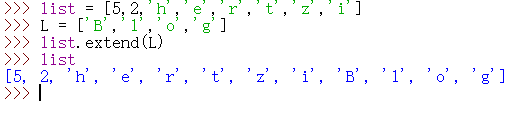
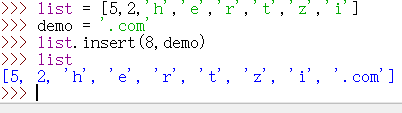
列表指定位置添加元素
1 | list = [5,2,'h','e','r','t','z','i'] |
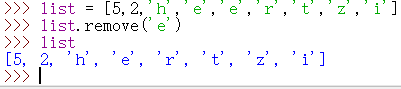
删除列表中首次出现的指定元素
1 | list = [5,2,'h','e','e','r','t','z','i'] |
删除并返回列表中指定下标的元素
1 | list = [5,2,'h','e','e','r','t','z','i'] |

1 | list = [5,2,'h','e','e','r','t','z','i'] |

返回指定元素在列表 list 中出现的次数
1 | list = [5,2,'h','e','e','r','t','z','i'] |

将列表中的所有元素逆序
1 | list = [5,2,'h','e','r','t','z','i'] |

对列表中的元素进行排序
1 | list = [2,3,4,3,1,2,8,7] |
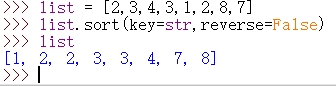
1 | ##降序 |

元组
元组也是Python的一个重要序列结构。从形式上来看,元组中的所有元素都放在一对圆括号中,元素之间用逗号隔开。
1 | tuple = (5,2,'h','e','r','t','z','i') |

元组与列表不同,元组属于不可变序列,一但创建后便无法对元素经行增删改查,但是对元素的访问速度要比列表快的多。由于不能更改元组中的元素,其代码也更加安全。
字典
Python中的字典包含若干“键:值”元素的可变序列,字典中的每一个元素都包含用冒号分开的“键”和“值”,不同元素之间用逗号隔开,所有元素放在一堆大括号中 “ { ” 和 “ } ” 中 。另外需要注意的是字典中的“键”不能重复,而“ 值 ”可以重复。
通过dic()创建字典
1 | dic = {'type':'Security','url':'https://52hertzi.com'} |

修改字典中的元素
1 | dic = {'name':'张三','age':20,'sex':'male'} |
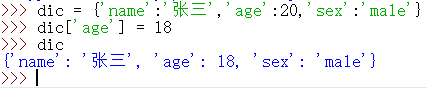
为字典添加新元素
1 | dic = {'name':'翠花','age':20,'sex':'female'} |

返回字典中的所有元素
1 | dic = {'name':'Tom','age':'22','sex':'male','addr':'USA'} |

删除字典中的元素
1 | dic = {'name':'Tom','age':'22','sex':'male','addr':'USA'} |

Python控制结构
常见的编程语言通常包含三大控制结构:顺序结构、选择结构和循环结构。
选择结构
在编程时,当需要根据条件表达式的值确定下一步的执行流程时,通常会用到选择结构。
最为常用的选择结构语句是if语句。
举例:输入学生成绩,60以下不及格,60到80良好,80以上则为优秀
1 | studentscore = int(input('输入学生成绩:')) |
选择结构
在python中主要有两种类型的循环结构:for循环和while循环。for循环一般用于有明显边界范围的情况,例:计算1+2+3+…+100的求解。while循环一般应用于循环次数难以确定的情况。
for循环
求解1+2+3+….+100
1 | sum = 0 |

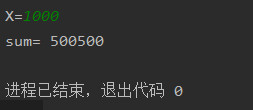
while循环
当循环次数无界限时通常使用while循环。如当输入变量不固定时,即求1+2+3+…+x的和时。
1 | x = int(input('X=')) |
文件处理
文件就像一个仓库,可以存储各种各样的数据,在文本文件中存储的是常规字符串,由文本行组成,每行通常由换行符” \n “ 结尾。
打开文件并创建对象
在python中内置了文件对象,通过open()函数就可以打开指定文件,并创建文件对象。
1 | open(file[,mode = 'r'[,buffering=-1]]) |
对文件内容进行操作
对文件的操作包括:文件的读取、写入、追加,以及设置采用二进制模式、文本模式、读写模式等。
向文本中写入内容
如果需要向文本文件进行读写操作,在打开文件时就需要指定文件的打开方式为写模式。根据不同的开发需求选取不同的写入模式:
1、w: (写入模式)
如果文件存在,则先清空文件内容,如果文件不存在则创建文件
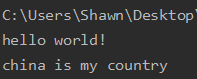
1 | s = 'hello word! \n' |

2、x:(写入模式)
创建新文件,如果文件存在则抛出异常
3、a:(追加模式)
也是写入模式 的一种,不覆盖文件的原始内容。
1 | s = 'china is my country \n' |

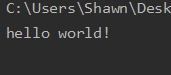
读取文件中的内容
有时需要加载文本中的某行或者全部内容,此时就需要用到文本的读操作。
1、r:(读模式,默认模式,可省略)
如果文件不存在,则抛出异常
1 | f = open('hello.txt','r') |
1 | f = open('hello.txt','r') |
关闭文件对象
当操作完文件后,一定要关闭文件对象,这样才能确保所做的修改都保存到了文件当中。
1 | f.close() |
- 文件操作一般都遵循”打开–>读写–>关闭”的基本流程。
- 如果读写操作代码引发异常,就很难保证文件能够被正常关闭。
- 可以使用上下文管理关键字with来避免这个问题。
- 关键字with能够自动管理资源,总能保证文件正确关闭。
利用with关键字向文件hello.txt继续追加”come baby”
1 | with open ('hello.txt','a') as f: |
异常处理结构
对于每一种高级语言来说,异常处理结构不仅能够提高代码的鲁棒性 ,而且提高了代码的容错性,从而不会因为使用者的错误输入而造成系统崩溃,也可以通过异常处理结构为使用者提供更加有好的错误提示。
引发程序异常的原因有很多种,较为常见的由除0,下标越界等。
Python中提供了很多不同形式的异常处理结构,其基本思路都是先尝试执行代码,再处理可能发生的错误。
try…except…结构
在python异常处理结构中,try…except…结构使用的最为频繁,其中try子句中的代码块为可能引发异常的语句,except子句用来捕获相应的异常。
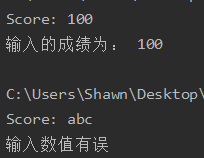
例如:当使用成绩录入系统录入成绩时,要求输入0–100的整数型值,而不接受其他类型的数值,如果输入的值超过0–100的范围,则给出提示
1 | score = int(input('Score:')) |
try…except…else…结构
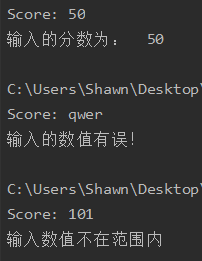
上面的例子try…except…结构和if语句来判断学生的分数成绩是否在0–100范围中,也可以通过try…except…else…结构进行编写。如果try代码的子句出现了异常且该异常被except捕获,则可以执行相应的异常处理代码,此时就不会执行else中的子句;如果try中的代码没有抛出异常,则继续执行else子句。
1 | score = input('Score: ') |
try…except…finally…结构
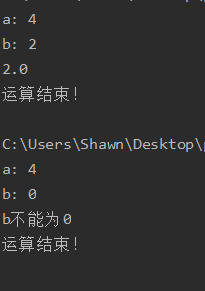
在try…except…finally…结构中,无论try子句是否正常执行,finally子句中的代码总会得到执行。该结构常用来做清理工作,释放try子句中申请的资源。
输入两个数值a,b进行除法运算,并输出最终结果。同时为了确保程序的鲁棒性,要求带有异常处理结构。
1 | a = int(input('a: ')) |
python 正则表达式(re模块)
level 1–找到固定值
1 | import re |
Print out:
[‘123456’]
level 2–某一类字符
1 | import re |
Print out:
[‘180’, ‘75’, ‘123456’]
\d匹配数字,后面加上+号表示数字可以出现1到多,连续输出
\D匹配非数字
\w所有字母数字,+号则可连续
\W非字母数字
level 3 –重复某一类字符
1 | import re |
translate:
{1,3}匹配3个以内的字符,eg:1,12,123,2,22,234
{1,}匹配大于等于1个的字符,eg:1,12,123,1234
{,3}匹配零到3个的字符,eg:1,23,123
level 4–组合level 2
1 | import re |
print out:
[‘0123-12345678’]
translate:
\d{4}-\d{8}先匹配四个字符,然后匹配一个横杠,再匹配八个字符
level 5 –多种情况
匹配座机与手机号码
1 | import re |
print out:
[‘0123-12345678’, ‘13300001111’]
translate:
1\d{10}1开头然后后面跟十个数字
|表示或的关系
level 6–指定位置
1 | import re |
print out:
[‘13300001111’]
translate:
^在表达式的最开始使用^符,表示一定要在句子的开头(起始符)
$表示结尾(结束符 )
level 7 –内部约束
找到barbar、dardar的前后三个字母重复的字符串
1 | import re |
print out:
[(‘bar’, ‘bar’), (‘car’, ‘car’), (‘dar’, ‘dar’)]
tanslate:
\w{3}表示三个字符,放在小括号中就成为了一个分组,而后面的(\1)表示它里面的内容和第一个括号里的内容必须相同,其中的1表示第一个括号,也就是说三个相同的字符要重复出现两次
语法规则汇总
字符类别
| 正则 | 匹配 |
|---|---|
| a,b,c,d | 字符常量,写什么就匹配什么 |
| \d | 一个数字 |
| \D | 一个非数字字符 |
| \s | 一个空格 |
| \S | 一个非空格 |
| \w | 一个任意字母数字下划线字符 |
| \W | 一个除了一个任意字母数字下划线字符 |
| [abcd] | 其中的任意一个字符 |
| [a-z] | a到z的任意一个字符 |
| 正则 | 匹配 |
|---|---|
| [^a-b] | 取反,除其中任意一个字符 |
| [\b] | 退格符号 |
| . | 统配符:除换行\n之外的任意一个字符 |
重复次数
| 正则 | 匹配 |
|---|---|
| * | 0或多个 |
| + | 1或多个 |
| ? | 0或1个 |
| {2} | 2个 |
| {2,5} | 2到5个 |
| {2,} | 至少2个 |
| {,5} | 最多5个 |
组合模式
| 正则 | 匹配 |
|---|---|
| \d{6}[a-z]{6} | 6个数字后面跟着6个小写字母 |
| \d{3}|[a-z]{6} | 3个数字或者6个小写字母 |
| (abc){3} | 表示abcabcabc |
指定位置
| 正则 | 匹配 |
|---|---|
| ^ | 字符串开头 |
| \A | 字符串开头,忽略m标记 |
| $ | 字符串行尾 |
| \Z | 字符串行尾,忽略m标记 |
| \b | 单词边界 |
| \B | 非单词边界 |
| (?=….) | 匹配….出现在之后的位置 |
| (?!….) | 匹配….不出现在之后的位置 |
| (?<=….) | 匹配….出现在之前的位置 |
| (?<!….) | 匹配….不出现在之前的位置 |
| (?()|) | 条件语句 |
分组
| 正则 | 匹配 |
|---|---|
| (….) | 捕获一个组 |
| (?P |
捕获组名为Y |
| (?:…) | 不捕获组 |
| \Y | 匹配第Y个匹配到的组 |
| (?P=Y) | 匹配名Y的组 |
| (?#…) | 注释 |
其他
| 正则 | 匹配 |
|---|---|
| i | 忽略大小写 |
| m | ^和$匹配行首和行尾 |
| S | 匹配换行符 |
| x | 允许换行和注释 |
| \L | 由当前语言区域决定\w,\W,\b,\B和大小写敏感匹配 |
| \u | Unicode匹配 |
| (?iLmsux) | 在正则表达中设置标记 |
re的模块
| 模块 | 方法 |
|---|---|
| re.search() | 查找符合模式的字符,只返回一个,返回Match对象 |
| re.match() | 和search一样,但是必须从字符串开头匹配 |
| re.findall() | 返回所有匹配的字符串列表 |
| re.finditer() | 返回一个迭代器,其中包含所有的匹配,也就是Match对象 |
| re.sub() | 替换匹配的字符,返回替换完的文本 |
| re.subn() | 替换匹配的字符串,返回替换完成的文本和替换的次数 |
| re.split() | 用匹配表达式的字符串做分隔符分割原字符串 |
| re.complie() | 把正则表达式编译成一个对象,方便后面使用 |






